
目的
データ分析の仕事をする際はPythonで専用スクリプトを書いて
大量のデータを一括処理するなんてことをよくやりますが、
今後は画像データに対する処理のスキルも習得する必要性が
出てきました。そこで、上記の書籍から画像データに対する
前処理のやり方をいろいろ学んだので、それらを忘れないように
まとめておくことにします。
目次
- 目的
- 目次
- 画像ファイルを読み込む
- 配列のサイズを確認する
- ピクセル値を確認する
- 機械学習のためのデータセット作成
- モルフォロジー変換
- ピクセル値のヒストグラム化
- t-SNEによる次元圧縮
- 訓練データとテストデータへの分割
- 画像データの水増し
画像ファイルを読み込む
このようにして画像ファイルを読み込むことができます。
BGR(青・緑・赤)の順にピクセル値が縦サイズ×横サイズの
配列として格納されます。
jpg_path = tkfd.askopenfilename(filetypes=[("JPG", "*.jpg")]) img = cv2.imread(jpg_path)
そして、shapeを使うと、読み込んだ画像の縦横サイズと
カラーチャンネルの数をこのように確認できます。
print(img.shape) # output (705, 646, 3)
配列のサイズを確認する
print(len(img)) # 配列全体のサイズ print(len(img[0])) # 1行目の配列のサイズ print(len(img[0][0])) # 1行目1列目の配列のサイズ
ピクセル値を確認する
カラー画像
先に示したような配列形式では分かりにくいため、
データフレーム形式でBGRそれぞれのピクセル値を
このようなコードで確認できます。
b, g, r = cv2.split(img) b_df = pd.DataFrame(b) print(b_df.shape) print(b_df.head())
例えば、B(青)のピクセル値はこのように出力されます。
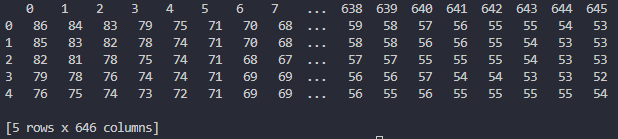
グレースケール画像
カラーではなく、明るさの度合いを表す輝度で表現される
画像をグレースケール画像といいます。グレースケール画像を
読み込んだときは、輝度についての0~255のピクセル値が
配列で格納されます。
こちらのコードで、カラー画像をグレースケール画像に
変換して読み込むことができます。
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) print(gray_img.shape) plt.imshow(gray_img, cmap="gray") plt.show()
2値化画像
2値化画像とは、グレースケール画像よりもさらに情報を落とし、
特徴量を際立たせたものです。ピクセル値が閾値より大きければ
白(255)、小さければ黒(0)を割り当てることで白黒画像に変換します。
こちらのコードにより、グレースケール画像を2値化画像に変換する
ことができます。thresholdの第一引数に2値化したい画像、第二引数に
閾値、第三引数に最大値を指定しています。
ret, bin_img = cv2.threshold(gray_img, 128, 255, cv2.THRESH_BINARY) plt.imshow(bin_img, cmap="gray") plt.show()
データフレーム形式でピクセル値を表示してみると、このように個々の
値が0 or 255に変換されることが分かります。
bin_df = pd.DataFrame(bin_img) print(bin_df.shape) print(bin_df.head())
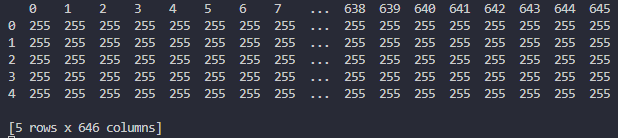
機械学習のためのデータセット作成
各種画像のピクセル値は、機械学習における分類モデルを作成する
ための特徴量として利用できます。そのためには、学習アルゴリズムが
受け付けられる形へデータを整形してやる必要があります。
整形のやり方にもいろいろありますが、一番理解しやすいのは、
1行に1枚の画像のピクセル値をフラットに並べ、それと画像の
被写体ラベルを関連付けるやり方です。
並べたピクセル値は説明変数、被写体ラベルは目的変数となり、
こちらのコードで実現できます。
# define data set array pixels = [] labels = [] # select directory selected_dir = tkfd.askdirectory() # append pixel value and label of each image to data set array for current_dir, sub_dirs, file_list in os.walk(selected_dir): if len(sub_dirs) > 0: for i, d in enumerate(sub_dirs): sub_dir_path = current_dir + '/' + d files = os.listdir(sub_dir_path) for f in files: img = cv2.imread(sub_dir_path + '/' + f, 0) img = cv2.resize(img, (128, 128)) img = np.array(img).flatten().tolist() # convert 2d array to 1d array pixels.append(img) labels.append(i) # convert data set from list to dataframe pixels_df = pd.DataFrame(pixels) pixels_df = pixels_df / 255 # normalize pixel between 0 and 1 labels_df = pd.DataFrame(labels) labels_df = labels_df.rename(columns={0: "label"}) img_set = pd.concat([pixels_df, labels_df], axis=1) print(img_set.head())
ピクセル値は0~1の間となるように正規化したデータフレーム
とし、最後に被写体ラベルのデータフレームを横方向に結合
させています。
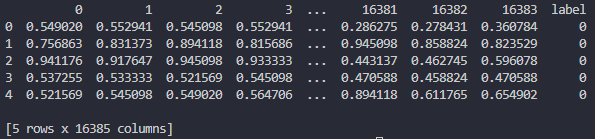
モルフォロジー変換
2値化した画像に対して、収縮、膨張、オープニング、
クロージングなどの処理を行うことをモルフォロジー変換と
いいます。
収縮(Erosion)
収縮は、前景物体の境界が侵食されていくような処理であり、
常に白色の前景物体を残すようにします。
画像に対してフィルタをスライドし、フィルタ内のピクセル値が
全て1だったときだけ「1」を出力し、そうでなければ「0」を
出力します。
物体の境界付近のピクセル値が白から黒になり、消えてしまうので、
結果として白い画素が占める領域が収縮するように見えるのが特徴です。
img = cv2.imread("gray_scale_image.jpg", 0) ret, bin_img = cv2.threshold(img, 128, 255, cv2.THRESH_BINARY) plt.imshow(bin_img, cmap="gray") kernel = np.ones((3, 3), np.uint8) img_el = cv2.erode(bin_img, kernel, iterations=1) plt.imshow(img_el, cmap="gray") plt.show()
収縮処理をする前
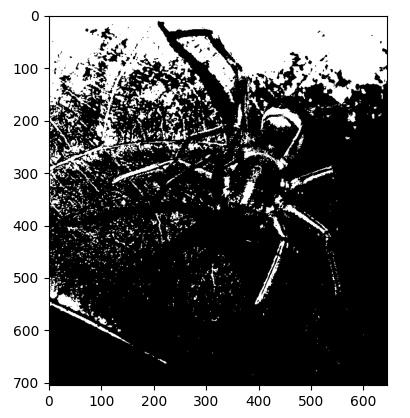
収縮処理をした後
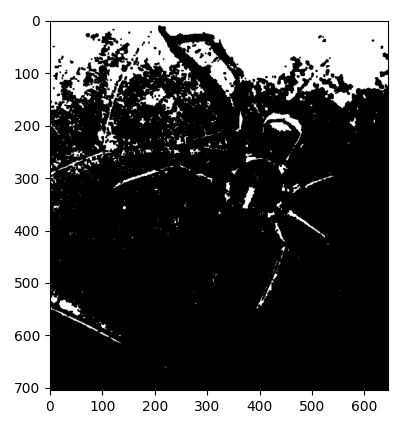
膨張(Dilation)
膨張は収縮の逆の処理です。フィルタ内のピクセル値が一つでも1であれば
「1」を出力します。これにより、画像中の白色の領域を増やすことができ
ます。普通は収縮をまず行うことでノイズを消し、そのあとに膨張させる
という使い方をします。
img_dl = cv2.dilate(bin_img, kernel, iterations=1) plt.imshow(img_dl, cmap="gray")
膨張処理をした後
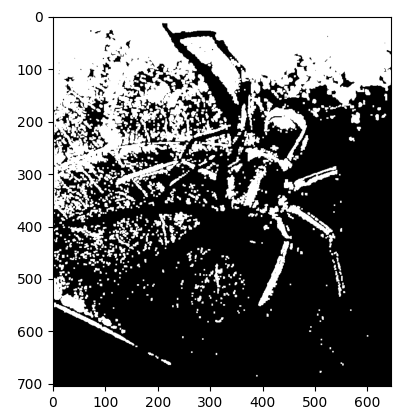
オープニング(Opening)
収縮後に膨張をする処理をオープニング処理といいます。
上記にもあるようにノイズ除去に有効な処理です。
img_op = cv2.morphologyEx(bin_img, cv2.MORPH_OPEN, kernel)
plt.imshow(img_op, cmap="gray")
オープニング処理をした後
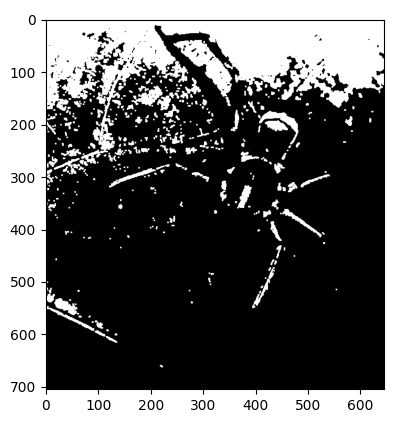
クロージング(Closing)
オープニングの逆の処理として、膨張の後に収縮をする処理を
クロージング処理といいます。オープニングと同様にノイズ除去に
有効ですが、特に前景領域中の小さな黒い穴を埋めるのに役立ちます。
img_cl = cv2.morphologyEx(bin_img, cv2.MORPH_CLOSE, kernel)
plt.imshow(img_cl, cmap="gray")
クロージング処理をした後
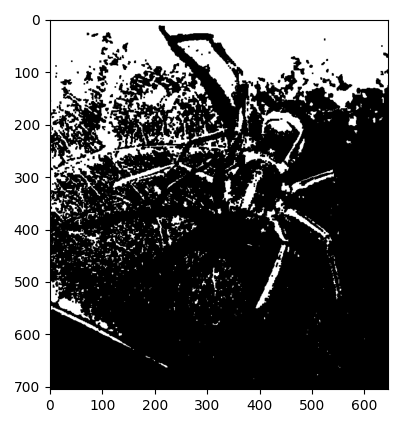
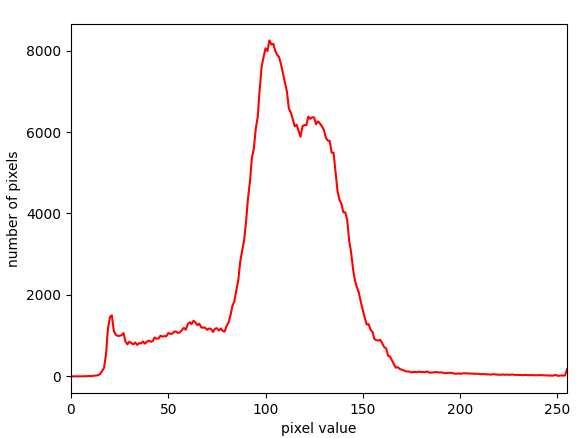
ピクセル値のヒストグラム化
横軸にピクセル値、縦軸にそのピクセル値を持つピクセルの数を
取ったヒストグラムを特徴量として扱う方法もあります。
hist_gr, bins = np.histogram(img.ravel(), 256, [0, 256]) plt.xlim(0, 255) plt.plot(hist_gr, "-r") plt.xlabel("pixel value") plt.ylabel("number of pixels")
このように、特定のピクセル値を持つピクセルの数が突出している
ことから、画像の明るい・暗い・見やすい・見にくいといった特徴を
把握することができます。
t-SNEによる次元圧縮
教師なし学習アルゴリズムの1つであり、高次元データを圧縮し
可視化する際に利用されます。データ間の距離を確率分布で表現し、
次元圧縮前後の確率分布のKL情報量が最小になる、圧縮後のデータ点
を計算するというものです。
t-SNEのアルゴリズムについての詳細はこちらの解説が詳しいです。
blog.albert2005.co.jp
また、評価指標として利用されるKL(カルバック・ライブラー)情報量に
ついてはこちらの記事で詳しく説明されています。
ogyahogya.hatenablog.com
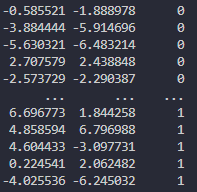
こちらのようなコードにより、データサイズが397行・16384列
あったデータフレームが、t-SNEの適用により397行・2列まで
圧縮することができます。
tsne = TSNE(n_components=2) # instance to compress 2-dimension pixels_tsne = tsne.fit_transform(pixels_df) print(pixels_df.shape) print(pixels_tsne.shape) img_tsne = pd.concat([pd.DataFrame(pixels_tsne), labels_df], axis=1) print(img_tsne.head)
圧縮後のデータ
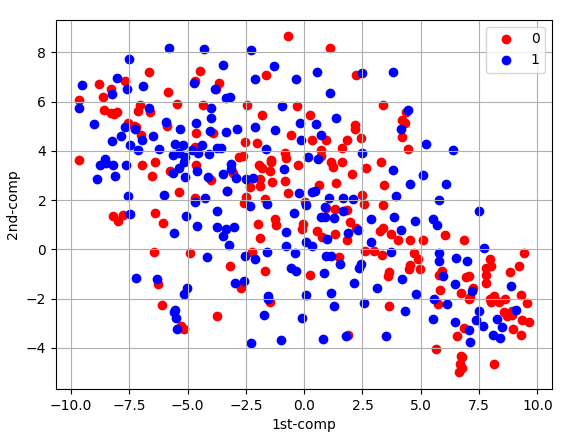
そして、圧縮したデータをこちらのコードで可視化すると
このようになります。
img_set_tsne_0 = img_set_tsne[img_set_tsne["label"] == 0] img_set_tsne_0 = img_set_tsne_0.drop("label", axis=1) plt.scatter(img_set_tsne_0[0], img_set_tsne_0[1], c="red", label=0) img_set_tsne_1 = img_set_tsne[img_set_tsne["label"] == 1] img_set_tsne_1 = img_set_tsne_1.drop("label", axis=1) plt.scatter(img_set_tsne_1[0], img_set_tsne_1[1], c="blue", label=1) plt.xlabel("1st-comp") plt.ylabel("2nd-comp") plt.legend() plt.grid() plt.show()
散布図による可視化
訓練データとテストデータへの分割
機械学習では、学習の元になるデータセットを訓練データと
テストデータに分割し、訓練データからモデルを学習し、
テストデータによって精度を検証します。
kimamani89.com
こちらのコードのようにすれば、手持ちのデータセットを
訓練データとテストデータを8:2の割合で作成することが
できます。
# split data into train, test data pixels = np.array(pixels) / 255 pixels = pixels.reshape([-1, 128, 128, 1]) labels = np.array(labels) print(pixels[0].shape) # size of an image is (lon, lat, ch) print(labels[0]) # 80%: train data, 20%: test data train_x, test_x, train_y, test_y = model_selection.train_test_split(pixels, labels, test_size=0.2) print(len(train_y)) print(len(test_y))
画像データの水増し
学習には多くのデータが必要になりますが、限られたデータしか
手持ちがないときは、反転や平滑化といった処理を加えた画像を
生成することでデータを水増しするという方法があります。
反転
水増しをする一つ目の手法は反転です。上下や左右の反転で
向きを変えた画像を学習させることにより、実際に向きが違う
画像が与えられた場合でも正しく判定できる可能性が高くなります。
反転の処理はこちらのコードで行うことができます。
x_img = cv2.flip(img, 0) # up/down y_img = cv2.flip(img, 1) # right/left xy_img = cv2.flip(img, -1) # up/down/right/left
平滑化
2つ目は平滑化です。画像中のノイズを除去するために用いられます。
こちらのコードで実行できます。
blur_img = cv2.blur(img, (5, 5)) gau_img = cv2.GaussianBlur(img, (5, 5), 0) med_img = cv2.medianBlur(img, 5)
このコードでは、5 × 5のサイズのフィルタを使用しています。
また、平滑化には下記の3つの手法を実行しています。
- 重みが一様なフィルタで領域内のピクセル値の平均を取る
- ピクセル値との距離に応じて、ガウス分布に従って重みを付与
- 領域内のピクセル値の中央値を取る
明るさの変更
3つ目は明るさの変更です。こちらのコードで実行できます。
gamma = 0.5 # coefficient to change brightness # store result of adjustment into array lut = np.zeros((256, 1), dtype="uint8") for i in range(len(lut)): lut[i][0] = 255 * pow((float(i) / 255), (1.0 / gamma)) gamma_img = cv2.LUT(img, lut)